

Introduction
Unsupervised Learning Overview: In today’s data-driven world, businesses generate massive amounts of unstructured and unlabeled data. Unsupervised learning algorithms help extract hidden patterns in data without the need for manual labeling. Unlike traditional models, supervised vs unsupervised learning differs in that the latter reveals insights without predefined outputs. Whether you’re a data science beginner or part of an AI development company, applying unsupervised learning can unlock powerful, automated intelligence across your workflows.

What is Unsupervised Learning?
Unsupervised Learning is a type of machine learning technique where algorithms operate on data without labeled outcomes. The aim is to explore the structure of the data to extract meaningful patterns and organize it in a manner that makes sense.
Key Characteristics:
- No Labels: Unlike supervised learning, unsupervised learning doesn’t use output labels.
- Pattern Discovery: The primary goal is to discover hidden patterns, relationships, or clusters.
- Autonomy: Models learn autonomously without guidance.
Also Read – Introduction to Machine Learning
Why is Unsupervised Learning Important?
No Human Labeling Required
Manual data labeling is often a resource-heavy task involving significant time, cost, and human effort. Unsupervised learning bypasses this requirement by working with raw, unlabeled data, making it ideal for industries where annotated datasets are limited or unavailable. This autonomy accelerates deployment and eliminates the dependency on domain experts for labeling.
Exploratory Data Analysis (EDA)
Unsupervised learning is crucial for initial data exploration. Before building predictive models, analysts use clustering and dimensionality reduction techniques to identify hidden structures, relationships, or anomalies in the data. This enables better decision-making, data-driven strategy formulation, and model selection.
Real-World Applicability
- Fraud Detection: Identifying suspicious behaviors that deviate from norms.
- Customer Segmentation: Grouping users based on behavior, preferences, or demographics.
- Inventory Optimization: Detecting patterns in purchasing and supply chain data.
- Healthcare Diagnostics: Grouping patients with similar symptoms or outcomes.
Preprocessing and Feature Engineering
Unsupervised techniques help clean and structure messy datasets. Dimensionality reduction (like PCA) is commonly used to eliminate redundant features and noise, which enhances downstream supervised learning Techniques. models like feature clustering and transformation also support scalable machine learning pipelines and improve model interpretability.
Types of Unsupervised Learning
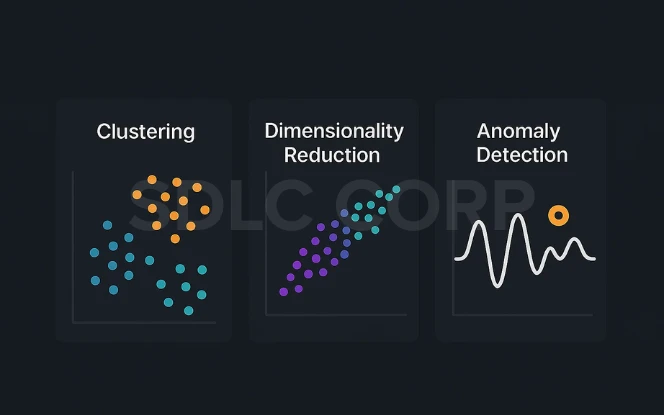
1. Clustering
Clustering involves grouping data points into clusters where members are more similar to each other than to those in other clusters.
K-Means Clustering
Hierarchical Clustering
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
2. Dimensionality Reduction
Reduces the number of features in a dataset while retaining essential information.
- Principal Component Analysis (PCA)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Autoencoders
3. Association Rule Learning
Discovers relationships between variables in large datasets.
- Apriori Algorithm
- Eclat Algorithm
4. Anomaly Detection
Identifies rare or unusual data points.
- Isolation Forests
- One-Class SVM
Core Algorithms Explained
K-Means Clustering
This algorithm partitions data into k distinct clusters. Each data point belongs to the cluster with the nearest mean (centroid). It’s widely used in market segmentation, document classification, and image compression.
Hierarchical Clustering
This method builds a hierarchy of clusters. It can be agglomerative (starting with individual points and merging them) or divisive (starting with one large cluster and splitting it). It’s ideal for datasets where a nested grouping structure is desirable, like in biological taxonomies.
DBSCAN
Unlike K-Means, DBSCAN doesn’t require specifying the number of clusters beforehand. It groups data points that are closely packed together, marking as outliers those points that lie alone in low-density regions. This makes it particularly effective for spatial data and discovering clusters of irregular shapes.
Principal Component Analysis (PCA)
PCA is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. It’s primarily used for dimensionality reduction, helping to reduce overfitting and improve model performance by focusing on the most significant variance in the data.
Autoencoders
These are a type of neural network designed for unsupervised learning of efficient data codings (or “representations”). They work by training the network to reconstruct its input. The hidden layer then learns a compressed representation of the input data. Autoencoders are excellent for noise reduction, dimensionality reduction, and anomaly detection in high-dimensional data.
Real-World Applications
1. Customer Segmentation
Businesses use clustering to identify customer groups with similar behavior, enabling personalized marketing strategies.
2. Anomaly Detection in Finance
Banks and fintech companies use UL to detect fraudulent transactions that deviate from the norm.
3. Recommendation Systems
E-commerce platforms like Amazon and Netflix use similarity analysis for product or content recommendations.
4. Image Compression
Dimensionality reduction techniques like PCA are employed in reducing image sizes without significant quality loss.
5. Document Categorization
Search engines and content management systems categorize large volumes of documents using topic modeling.
6. Bioinformatics
Used to discover patterns in genetic sequences, gene expression data, and protein structure.
Advantages of Unsupervised Learning

- No Labeled Data Needed: Saves significant time and effort in data preparation.
- Discovers Hidden Patterns: Uncovers non-obvious insights and data structures.
- Scales to Big Data: Efficiently processes large and complex datasets.
- Enhances Feature Engineering: Aids in data transformation and noise reduction for better model performance.
Challenges and Limitations
- Interpretability: Results can be hard to explain.
- Evaluation Difficulty: Lack of ground truth makes model validation tricky.
- Sensitivity to Initialization: Especially true for clustering algorithms like K-Means.
- Scalability Issues: Some algorithms struggle with large datasets.
Unsupervised vs. Supervised Learning
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Type | Labeled | Unlabeled |
| Goal | Predict Output | Discover Structure |
| Algorithms | Linear Regression, SVM | K-Means, PCA, DBSCAN |
| Output Type | Classification/Regression | Clustering, Association Rules |
| Examples | Spam Detection, Forecast | Customer Segmentation, Fraud |
Also Read – Large Language Models
Tools and Libraries
Scikit-learn: A popular Python library offering comprehensive tools for clustering, dimensionality reduction, and anomaly detection.
TensorFlow/Keras: Essential for building and training deep learning models like Autoencoders.
Matplotlib/Seaborn: Powerful Python libraries for visualizing data and the results of unsupervised learning algorithms.
H2O.ai: An open-source machine learning platform that provides scalable implementations of various algorithms, including those for unsupervised learning.
Orange: A visual programming software for data mining, offering an intuitive interface for unsupervised learning tasks without coding.

Conclusion
Unsupervised learning is a powerful machine learning paradigm that empowers systems to understand and organize data without human labels. From customer segmentation to fraud detection and dimensionality reduction, its use cases span industries and domains. While challenges like interpretability and evaluation exist, advancements in AI tools and hybrid learning models are mitigating them.
As data complexity increases, so does the importance of unsupervised learning. Organizations especially those guided by a strong AI development company can significantly benefit from these methods by gaining early insights and making informed decisions.
FAQs
Q1: What is the main goal of unsupervised learning?
A: Its primary goal is to find inherent structure, patterns, or groupings within unlabeled data without any prior knowledge of desired outputs.
Q2: Can unsupervised learning be used for prediction?
A: Not directly for predicting specific outcomes, but it helps indirectly by identifying underlying patterns or anomalies that can inform predictive models or enable detection tasks.
Q3: Which is better: supervised or unsupervised learning?
A: Neither is inherently “better”; their suitability depends entirely on your problem and available data. Supervised learning excels at predictions when labeled data is plentiful, while unsupervised learning is crucial for discovery and organization when labels are scarce or non-existent.
Q4: Is PCA supervised or unsupervised?
A: PCA (Principal Component Analysis) is an unsupervised dimensionality reduction technique. It finds patterns in the data to transform it without relying on any output labels.
Q5: Where are some popular real-world applications of unsupervised learning?
A: It’s widely used in areas like customer segmentation, fraud detection, recommendation systems, image compression, document categorization, and bioinformatics.
Q6: What are some of the most popular unsupervised algorithms?
A: Some of the most popular algorithms include K-Means Clustering, DBSCAN, Hierarchical Clustering, Principal Component Analysis (PCA), and Autoencoders.
Q7: Is unsupervised learning more difficult than supervised learning?
A: In some aspects, yes. The absence of ground truth (labels) makes model training and especially evaluation more challenging, as there’s no direct measure of “accuracy” against a known target.
Q8: Can unsupervised learning help in feature engineering?
A: Absolutely! It’s an excellent tool for feature engineering. Techniques like dimensionality reduction can create new, more informative features or reduce noise, which often significantly improves the performance of other machine learning models.
Q9: Are there hybrid approaches combining supervised and unsupervised learning?
A: Yes, semi-supervised learning is a prominent hybrid approach. It leverages a small amount of labeled data in conjunction with a large amount of unlabeled data to train models, combining the strengths of both paradigms.
Q10: What tools are commonly used for unsupervised learning?
A: Popular tools and libraries include Scikit-learn, TensorFlow, Keras, H2O.ai, and visual programming environments like Orange.












